
2 likes
·
1.6K reads
3 comments

I see many mistakes in this articles , few correction points :
1) machine learning is just a more sophisticated technique than usual code , and the result is just a fancy csv file ( usually call a model )
2) machine learning pipeline are not different than any other pipeline
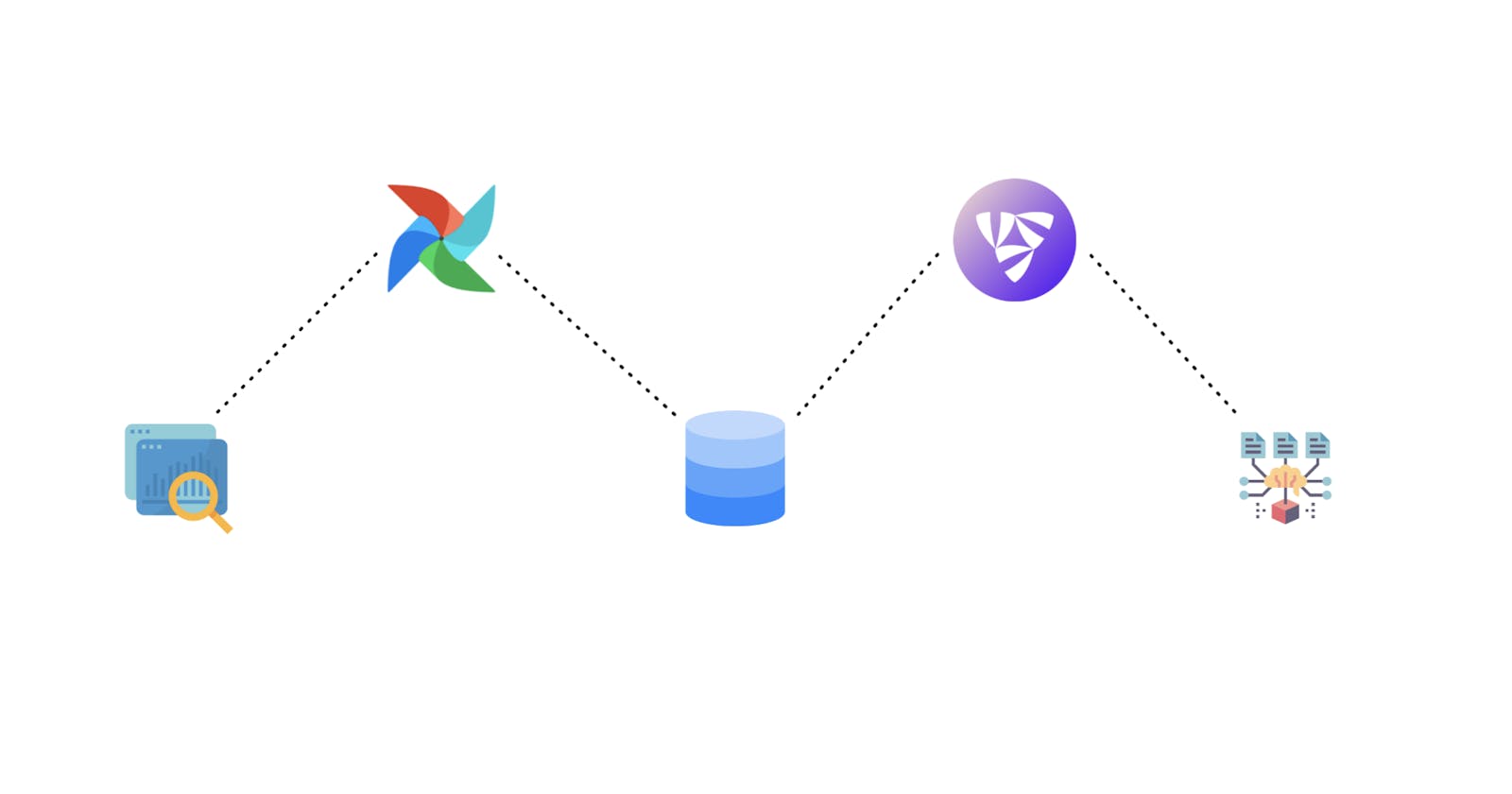
a simple business-rules jobs and a machine-learning jobs are both jobs that play with the data and
needs to run resource-intensive computations. needs data lineage in place or a data-aware platform to simplify the debugging process. needs code to be versioned to ensure reproducibility. needs infrastructure automation.
3) Resource-intensive tasks
Airflow have a KubernetesExecutor and KubernetesCeleryExecutor giving more flexibility than flyte
4) Versioning
in all case versioning is done with GIT and yes airflow can't keep under the same dag name two dag version. you must suffix your dag with a version number
5) Infrastructure automation
this doesn't make sense , flyte and airflow are not K8S , in all case it's K8S that is going to manage the Infrastructure
airlfow task or flyte task just have to explicit the hardware request of the pod to run
6) Caching
airflow have xcom_backend to store (in a custom storage like S3) the data that is returned by a job. IN ALL CASES it's a bad practice to return data from a job ( job must be capable of storing his own result itself )
I'm not going to continue , you are just trying to justifies why you created flyte more than just saying :
"flyte is another opinionated scheduling framework , you can try it but it's very similar to what is already existing"

Hi, raphael! Thanks for reading the blog post. Let me put forth my thoughts here.
1) machine learning is just a more sophisticated technique than usual code , and the result is just a fancy csv file ( usually call a model )
ML isn't "just" a sophisticated technique than usual code. The process involved in ML, be it feature engineering, training, or predictions are all more involved than typical software engineering code. I highlighted the differences in the ML vs. ETL tasks section.
2) machine learning pipeline are not different than any other pipeline
ML is quite different from other pipelines. The code aspect of ML isn't very different; however, data is a crucial dimension that needs to be handled. ML also needs some features more than software engineering, like caching, data lineage and infrastructure automation.
For example, an ETL job need not be reproducible. It's okay if it isn't. An ML job, however, needs reproducibility in place as it comprises expensive operations. It's kind of mandatory. The point I highlighted in the article was that ML needs so-and-so requirements to smoothen the pipelining process but ETL doesn't need all of them, i.e., it's okay to not have them.
3) Resource-intensive tasks
I did mention that Airflow has Kubernetes support. But it needs to be enabled to run resource-intensive tasks, and this is a blocker. Flyte's on top of K8s, so that's kind of built-in and you needn't worry about setting it up separately.
5) Infrastructure automation
I agree with you. K8s is the ultimate driver. Airflow isn't K8s-native, but Flyte is. Airflow doesn't provide a seamless way to automate infrastructure management. That was all I wanted to highlight.
6) Caching I'm sorry I didn't get your point. Why is it a bad practice to return data from a job? Are you talking about Airflow?
"flyte is another opinionated scheduling framework , you can try it but it's very similar to what is already existing"
Flyte isn't just a scheduling framework! It's more than that. It's an infrastructure, data, and ML orchestrator. I'd love for you to try out Flyte to get the hang of what it offers. :)

Re raphael's complaint # 6, the idea that a task should offload its result in some way other than returning it to the caller is one that makes sense in some contexts--but hardly in all cases.
In fact, there are many cases where that's called a "side effect" and much work has been done to create systems that don't let you do it (e.g. functional programming languages).